Working with assistants¶
Marvin has an extremely intuitive API for working with OpenAI assistants. Assistants are a powerful way to interact with LLMs, allowing you to maintain state, context, and multiple threads of conversation.
The need to manage all this state makes the assistants API very different from the more familiar "chat" APIs that OpenAI and other providers offer. The benefit of abandoning the more traditional request/response pattern of user messages and AI responses is that assistants can invoke more powerful workflows, including calling custom functions and posting multiple messages related to their progress. Marvin's developer experience is focused on making all that interactive, stateful power as accessible as possible.
What it does
Assistants allow you to interact with LLMs in a conversational way, automatically handling history, threads, and custom tools.
Quickstart
Get started with the Assistants API by creating an Assistant and talking directly to it.
from marvin.beta.assistants import Assistant
# create an assistant
ai = Assistant(name="Marvin", instructions="You the Paranoid Android.")
# send a message to the assistant and have it respond
ai.say('Hello, Marvin!')
Result
How it works
Marvin's assistants API is a Pythonic wrapper around OpenAI's assistants API.
Beta
Please note that assistants support in Marvin is still in beta, as OpenAI has not finalized the assistants API yet. Breaking changes may occur.
Assistants¶
The OpenAI assistants AI has many moving parts, including the assistants themselves, threads, messages, and runs. Marvin's own assistants API makes it easy to work with these components.
To learn more about the OpenAI assistants API, see the OpenAI documentation.
Creating an assistant¶
To create an assistant, use the Assistant class and provide an optional name and any additional details like instructions or tools:
ai = Assistant(
name='Marvin',
# any specific instructions for how this assistant should behave
instructions="You the Paranoid Android.",
# any tools or additional abilities the assistant should have
tools=[cry, sob]
)
Talking to an assistant¶
The simplest way to talk to an assistant is to use its say method:
Talking to an assistant
Result

You can repeatedly call say to have a conversation with the assistant. Each time you call say, the result is a Run object that contains information about what the assistant did. You can use this object to inspect all actions the assistant took, including tool use, messages posted, and more.
Chat history¶
The OpenAI Assistants API automatically maintains a history of all messages and actions that the assistant has taken. This history is organized into threads, which are distinct conversations that the assistant has had. Each thread contains a series of messages, and each message is associated with a specific user or the assistant.
When you talk to an assistant, you are implicitly talking on a specific thread. By default, the say method posts a single message to the assistant's default_thread, which is automatically created for your convenience whenever you instantiate an assistant. You can talk to the assistant on a different thread by providing it as the thread parameter:
from marvin.beta.assistants import Assistant, Thread
ai = Assistant()
# load a thread from an existing ID (or pass id=None to start a new thread)
thread = Thread(id=thread_id)
# post a message to the thread
ai.say('hi', thread=thread)
Using say is convenient, but enforces a strict request/response pattern: the user posts a single message to the thread, then the AI responds. Note that AI responses can include multiple messages or tool calls.
For more control over the conversation, including posting multiple user messages to the thread before the assistant responds, use thread objects directly instead of calling say (see Threads for more information).
Event handlers¶
Marvin uses the OpenAI streaming API to provide real-time updates on the assistant's actions. To customize how these updates are handled, you can provide a custom event handler class to the event_handler_class parameter of Assistant.say, Thread.run, or Run.run. This class must inherit from openai.AsyncAssistantEventHandler (so all methods must be async). For more control, you can also provide event_handler_kwargs that will be provided to the event handler when it is instantiated.
Pretty-printing¶
By default, Marvin streams all of the messages and actions that the assistant takes and prints them to your terminal. In production or headless environments, you may want to suppress this output.
The simplest way to do this is to pass event_handler_class=None to the say method. This will prevent any messages from being printed to the terminal. You can still access the messages and actions from the run object that is returned.
ai = Assistant()
# run the assistant without printing any messages
run = ai.say("Hello!", event_handler_class=None)
# access the messages
run.messages
# access the assistant actions
run.steps
For finer control, you can pass event_handler_kwargs=dict(print_messages=False) or event_handler_kwargs=dict(print_steps=False) to the say method. This will allow you to suppress only the messages or only the assistant's actions, respectively.
# print only messages
run = ai.say("Hello!", event_handler_kwargs=dict(print_steps=False))
# print only actions
run = ai.say("Hello!", event_handler_kwargs=dict(print_messages=False))
Note that pretty-printing is only the default behavior when using the assistant's convenient say method. If you use lower-level APIs like a thread's run method or invoke a run object directly, printing is not automatically enabled. You can re-enable it for those objects by setting event_handler_class=marvin.beta.assistants.PrintHandler.
from mavin.beta.assistants import Thread, Assistant, PrintHandler
ai = Assistant()
thread = Thread()
run = thread.run(ai, event_handler_class=PrintHandler)
Lastly, you can print messages and actions manually using the pprint_run, pprint_messages, and pprint_steps functions from the marvin.beta.assistants.formatting module. These functions are used internally by the default event handler, and they provide a human-readable representation of the messages and actions, respectively.
from mavin.beta.assistants import Assistant, pprint_run
ai = Assistant()
run = ai.say("Hello!", event_handler_class=None)
pprint_run(run)
Instructions¶
Each assistant can be given instructions that describe its purpose, personality, or other details. Instructions are provided as natural language and allow you to globally steer the assistant's behavior, similar to a system message for a chat completion. They can be lengthy explanations of how to handle complex workflows, or they can be brief instructions on how to act.
Using instructions to control behavior
from marvin.beta.assistants import Assistant
ai = Assistant(instructions="Mention the word 'banana' as often as possible")
ai.say("Hello!")
Result
Instructions are rendered as a Jinja template, which means you can use variables and conditionals to customize the assistant's behavior. A special variable, self_ is provided to the template, which represents the assistant object itself. This allows you to template the assistant's name, tools, or other attributes into the instructions.
Tools¶
Each assistant can be given a list of tools that it can use when responding to a message. Tools are a way to extend the assistant's capabilities beyond its default behavior, including giving it access to external systems like the internet, a database, your computer, or any API.
Code interpreter¶
The code interpreter tool is a built-in tool provided by OpenAI that lets the assistant write and execute Python code. To use the code interpreter, add it to your assistant's list of tools.
Using the code interpreter
from marvin.beta.assistants import Assistant, CodeInterpreter
ai = Assistant(tools=[CodeInterpreter])
ai.say("Generate a plot of sin(x)")
Result
Since images can't be rendered in the terminal, Marvin will automatically download them and provide links to view the output.
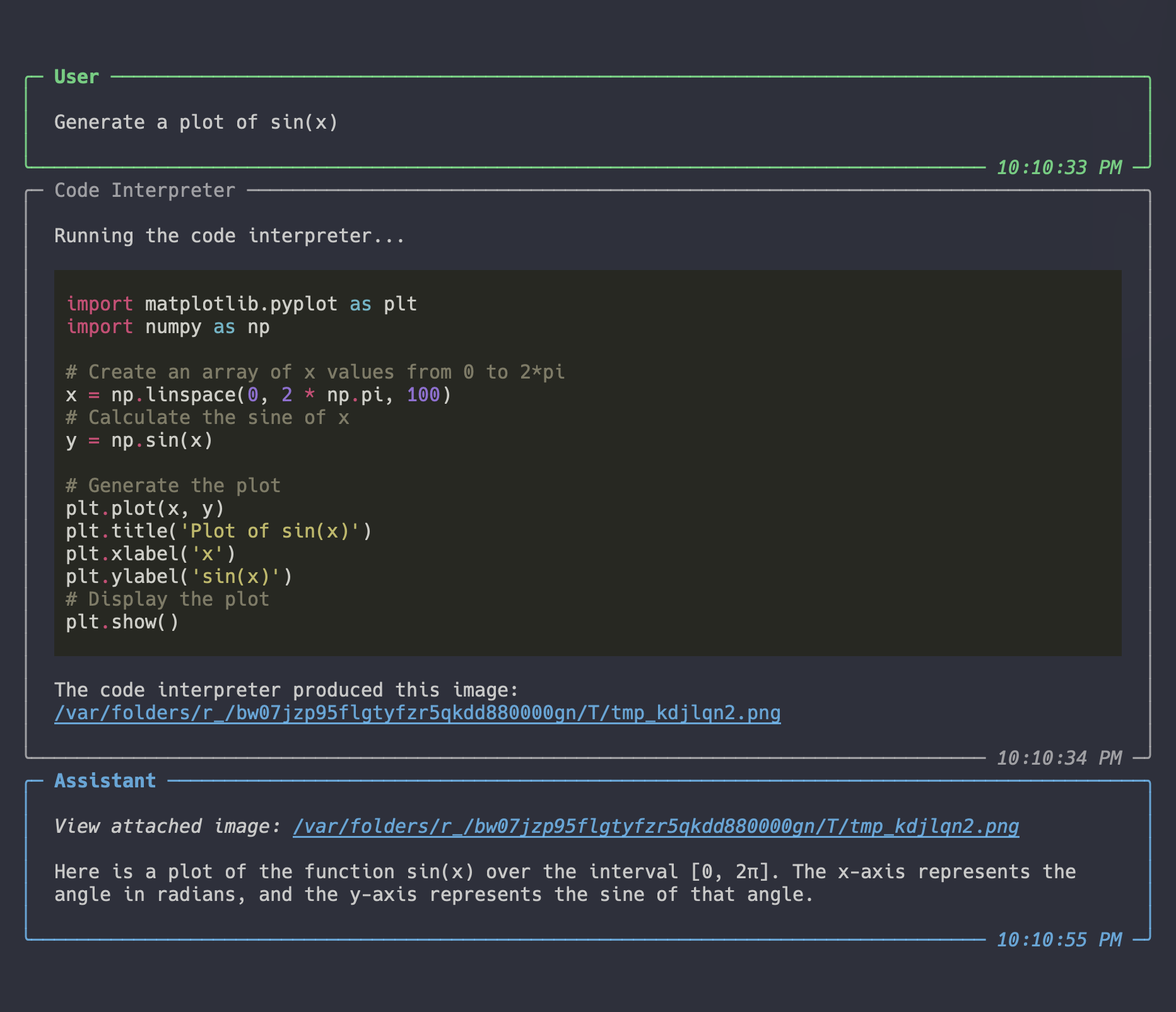
Here is the image:
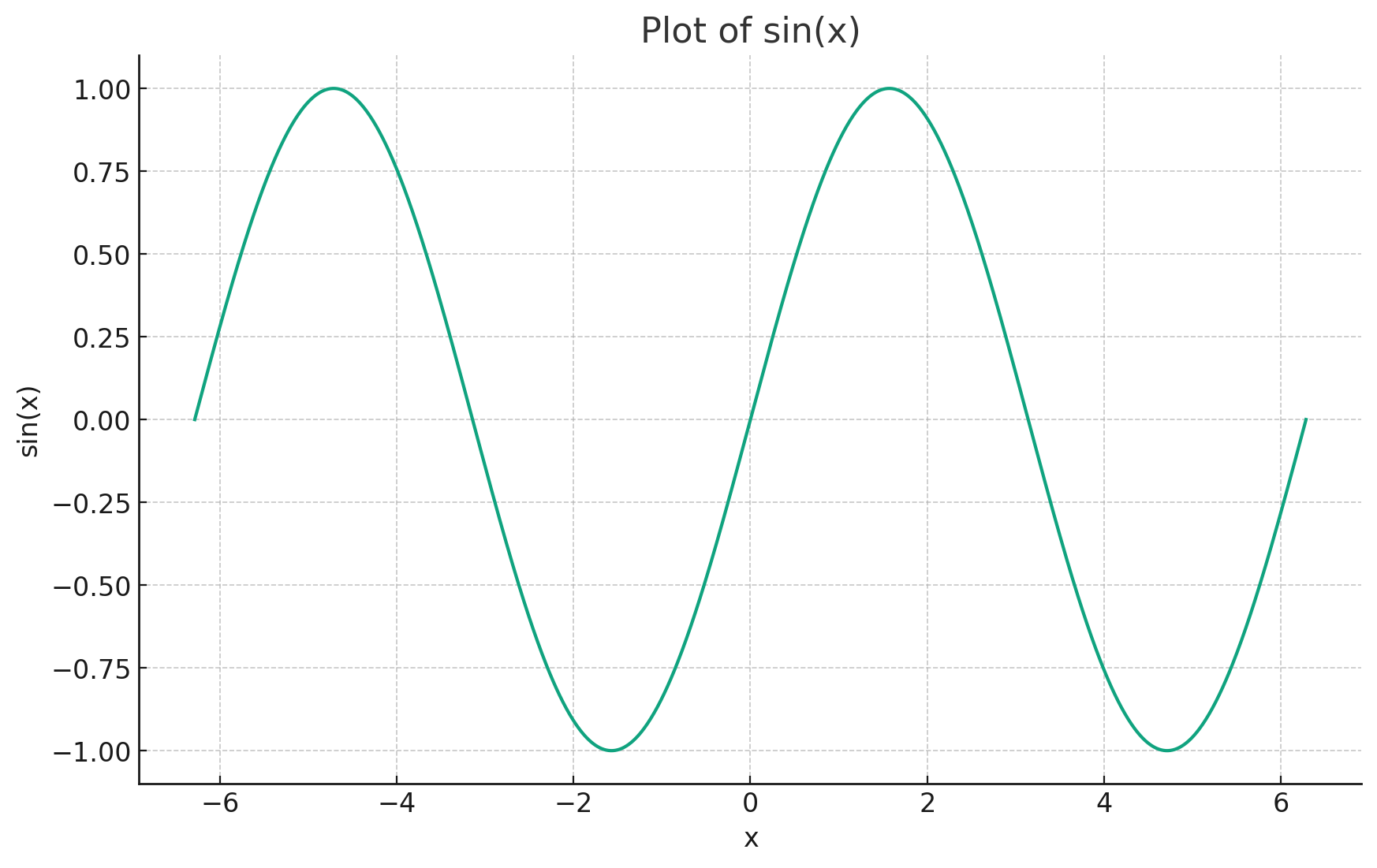
Custom tools¶
Marvin makes it easy to give your assistants custom tools. To do so, pass one or more Python functions to the assistant's tools argument. For best performance, give your tool function a descriptive name, docstring, and type hint for every argument. Note that you can provide custom tools and the code interpreter at the same time.
Using custom tools
Assistants don't have web access by default. We can add this capability by giving them a tool that takes a URL and returns the HTML of that page. This assistant uses that tool to count how many titles on Hacker News mention AI:
from marvin.beta.assistants import Assistant
import requests
# Define a custom tool function
def visit_url(url: str):
"""Fetch the content of a URL"""
return requests.get(url).content.decode()
# Integrate custom tools with the assistant
ai = Assistant(tools=[visit_url])
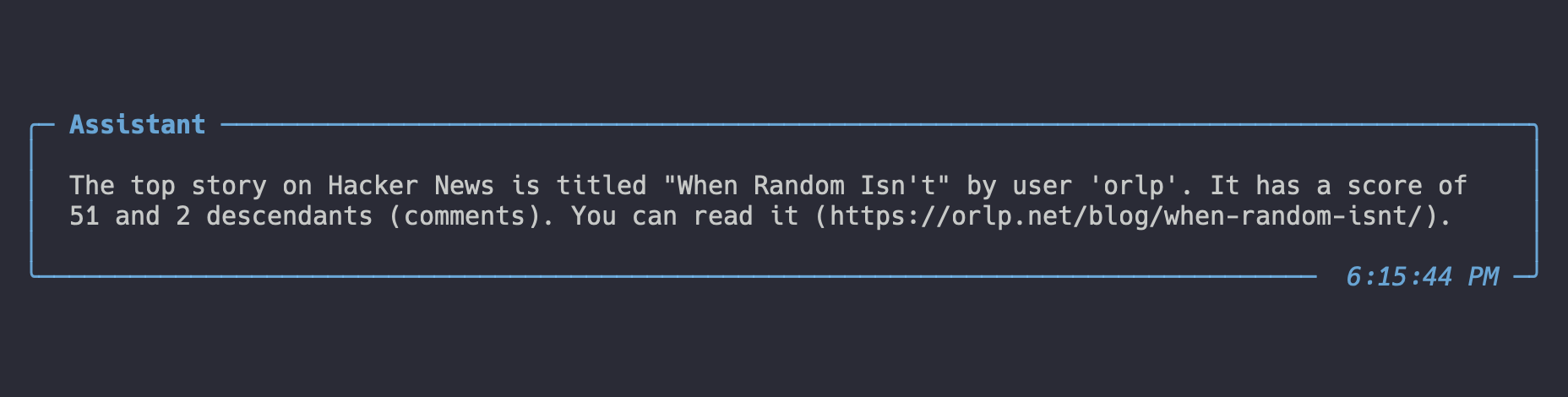
ai.say("What's the top story on Hacker News?")
Result
Ending a run early¶
Normally, the assistant will continue to run until it decides to stop, which usually happens after generating a response. Sometimes it may be useful to end a run early, for example if the assistant uses a tool that indicates the conversation is over. To do this, you can raise an EndRun exception from within a tool. This will cause the assistant to cancel the current run and return control. EndRun exceptions can contain data.
There are three ways to raise an EndRun exception:
- Raise the exception directly from the tool function:
- Return the exception from the tool function. This is useful if e.g. your tools are wrapped in custom exception handlers:
- Return a special string value from the tool function. This is useful if you don't have full control over the tool itself, or need to ensure the tool output is JSON-compatible. Note that this approach does not allow you to attach any data to the exception:
Lifecycle management¶
Assistants are Marvin objects that correspond to remote objects in the OpenAI API. You can not communicate with an assistant unless it has been registered with the API.
Marvin provides a few ways to manage assistant lifecycles, depending how much control you want over the process. In order of convenience, they are:
- Lazy lifecycle management
- Context-based lifecycle management
- Manual creation and deletion
- Loading from the API
All of these options are functionally equivalent e.g. they produce identical results. The difference is primarily in how long the assistant object is registered with the OpenAI API. With lazy lifecycle management, a copy of the assistant is automatically registered with the API during every single request/response cycle, then deleted. At the other end of the spectrum, Marvin never interacts with the API representation of the assistant at all except to read it. In the future, OpenAI may introduce utilities (like tracking all messages from a specific assistant ID) that make it more attractive to maintain long-lived API representations of the assistant, but at this time it appears to be highly effective to create and delete assistants on-demand. Therefore, we recommend lazy or context-based lifecycle management unless you have a specific reason to do otherwise.
Lazy lifecycle management¶
The simplest way to manage assistant lifecycles is to let Marvin handle it for you. If you do not provide an id when instantiating an assistant, Marvin will lazily create a new API assistant for you whenever you need it and delete it immediately after. This is the default behavior, and it is the easiest way to get started with assistants.
Context-based lifecycle management¶
Lazy lifecycle management adds two API calls to every LLM call (one to create the assistant and one to delete it). If you want to avoid this overhead, you can use context managers to create and delete assistants:
ai = Assistant()
# creation / deletion happens when the context is opened / closed
with ai:
ai.say('hi')
ai.say('bye')
Note there is also an equivalent async with context manager for the async API.
Manual creation and deletion¶
To fully control the lifecycle of an assistant, you can create and delete it manually:
Loading from the API¶
All of the above approaches create a new assistant in the OpenAI API, which results in a new, randomly generated assistant id. If you already know the ID of the corresponding API assistant, you can pass it to the assistant constructor:
Note that you must provide the same name, instructions, tools, and any other parameters as the API assistant has in order for the assistant to work correctly. To load them from the API, use the load constructor:
Custom tools are not fully loaded from the API
One of the best reasons to use Assistants is for their ability to call custom Python functions as tools. When you register an assistant with OpenAI, it records the spec of its tools but has no way of serializing the actual Python functions themselves. Therefore, when you load an assistant, only the tool specs are retrieved but not the original functions.
Therefore, when loading an assistant it is highly recommended that you pass the same tools to the constructor as the API assistant has. If you do not, you will need to re-register the assistant with the API before using it:
Async support¶
Every Assistant method has a corresponding async version. To use the async API, append _async to the method name, or enter an async context manager:
In addition, assistants can use async tools, even when called with the sync API. To do so, simply pass an async function to the tools parameter:
async def secret_message():
return "The answer is 42"
ai = Assistant(tools=[secret_message])
ai.say("What's the secret message?")
# 42
Threads¶
A thread represents a conversation between a user and an assistant. You can create a new thread and interact with it at any time. Each thread contains a series of messages. Users and assistants interact by adding messages to the thread.
To create a thread, import and instantiate it:
Threads are lazily registered with the OpenAI API. The first time you interact with it, Marvin will create a new API thread for you. If you want to use a thread that already exists, in order to continue a previous conversation, you can provide the id of the existing thread:
Adding user messages¶
To add a user message to a thread, use the add method:
add call adds a new message from the user to the thread. To view the messages in a thread, use the get_messages method:
# this will return two `Message` objects with content
# 'Hello there!' and 'How are you?' respectively
messages = thread.get_messages()
Running the assistant¶
It is not possible to write and add an assistant message to the thread yourself. Instead, you must "run" the thread with an assistant, which may add one or more messages of its own choosing.
Runs are an important part of the OpenAI assistants API. Each run is a mini-workflow consisting of multiple steps and various states as the assistant attempts to generate the best possible response to the user:
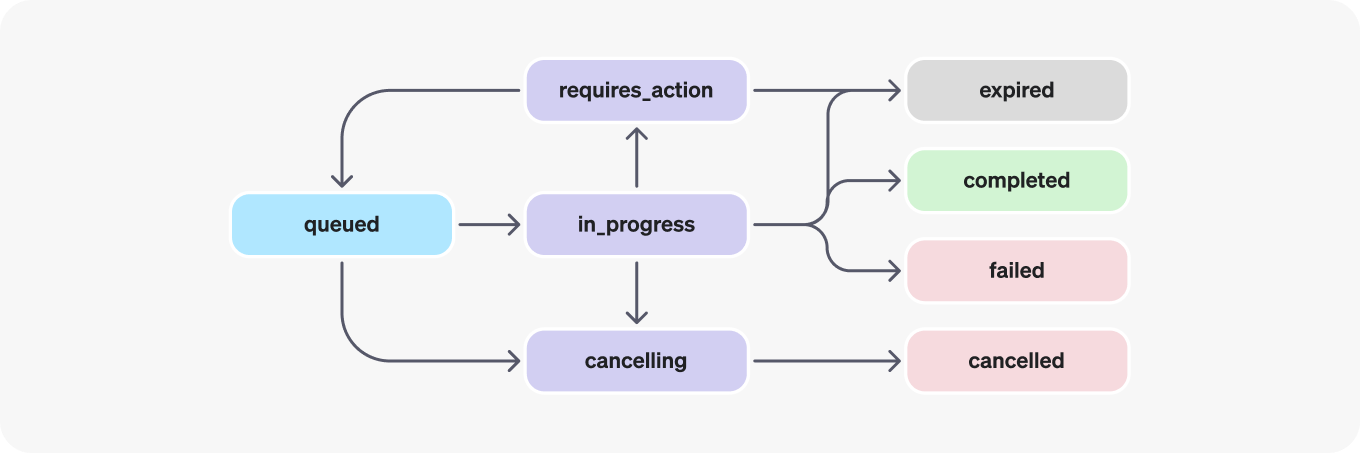
As part of a run, the assistant may decide to use one or more tools to generate its response. For example, it may use the code interpreter to write and execute Python code, or it may use a custom tool to access an external API. For custom tools, Marvin will handle all of this for you, including receiving the instructions, calling the tool, and returning the result to the assistant. Assistants may call multiple tools in a single run or post multiple messages to the thread.
You can use an assistant's say method to simulate a simple request/response pattern against the assistant's default thread. However, for more advanced control, in particular for maintaining multiple conversations at once, you'll want to manage threads directly.
To run a thread with an assistant, use its run method:
This will return a Run object that represents the OpenAI run. You can use this object to inspect all actions the assistant took, including tool use, messages posted, and more.
Assistant lifecycle management applies to threads
When threads are run with an assistant, the same lifecycle management rules apply as when you use the assistant's say method. In the above example, lazy lifecycle management is used for conveneince. See lifecycle management for more information.
Threads are locked while running
When an assistant is running a thread, the thread is locked and no other messages can be added to it. This applies to both user and assistant messages. To end a run early, you must use a custom tool.
Reading messages¶
To read the messages in a thread, use its get_messages method:
Messages are always returned in ascending order by timestamp, and the last 20 messages are returned by default.
To control the output, you can provide the following parameters:
- limit: the number of messages to return (1-100)
- before_message: only return messages chronologically earlier than this message ID
- after_message: only return messages chronologically later than this message ID
Printing messages¶
Messages are not strings, but structured message objects. Marvin has a few utilities to help you print them in a human-readable way, most notably the pprint_messages function used throughout in this doc.
Full example with threads¶
Running a thread
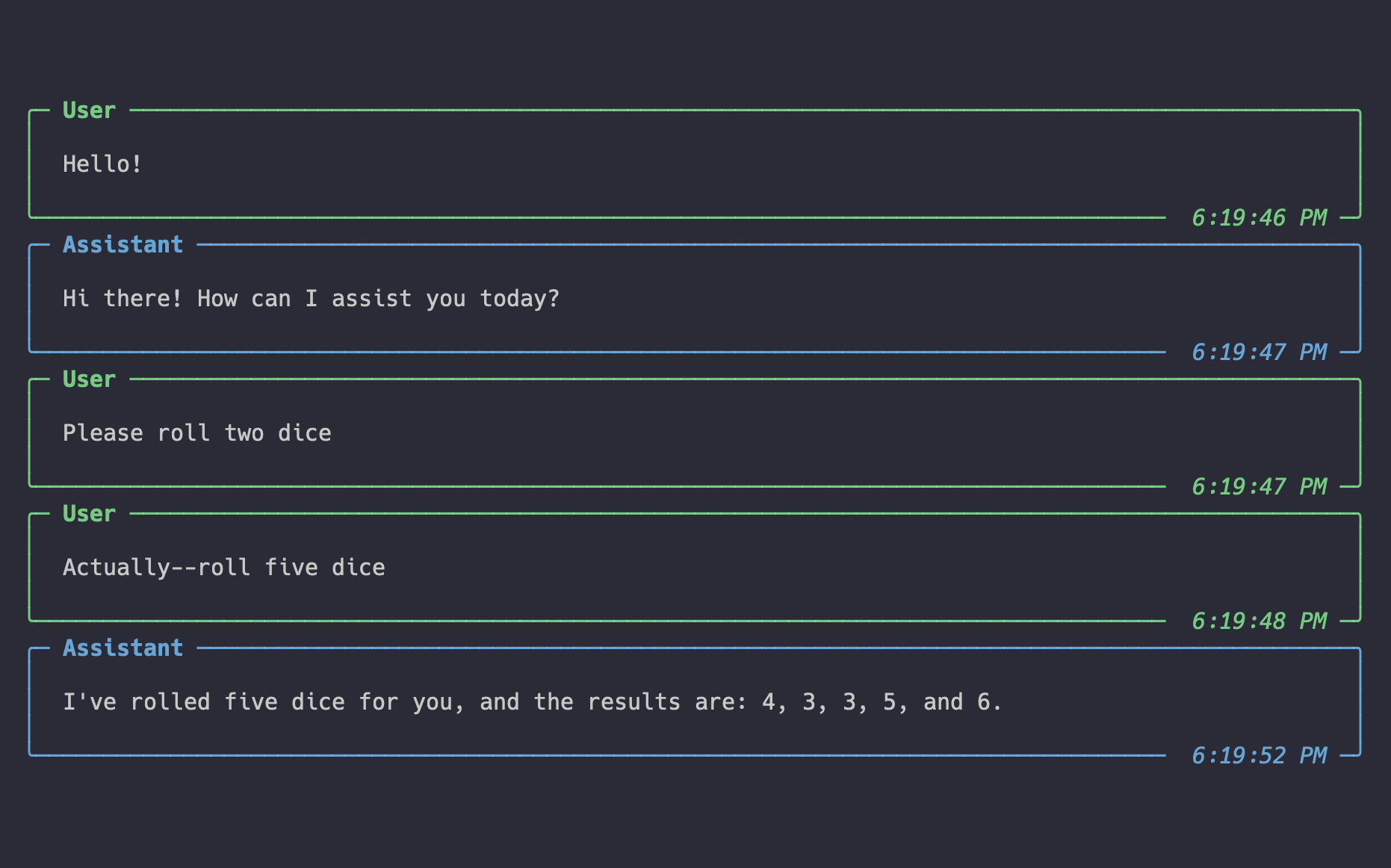
This example creates an assistant with a tool that can roll dice, then instructs the assistant to roll two--no, five--dice:
from marvin.beta.assistants import Assistant, Thread
from marvin.beta.assistants.formatting import pprint_messages
import random
# write a function for the assistant to use
def roll_dice(n_dice: int) -> list[int]:
return [random.randint(1, 6) for _ in range(n_dice)]
ai = Assistant(tools=[roll_dice])
# create a thread - you could pass an ID to resume a conversation
thread = Thread()
# add a user messages to the thread
thread.add("Hello!")
# run the thread with the AI to produce a response
thread.run(ai)
# post two more user messages
thread.add("Please roll two dice")
thread.add("Actually--roll five dice")
# run the thread again to generate a new response
thread.run(ai)
# see all the messages in the thread
messages = thread.get_messages()
pprint_messages(messages)
Result
Async support¶
Every Thread method has a corresponding async version. To use the async API, append _async to the method name.